DIONYSUS: A Pre-trained Model for Low-Resource Dialogue Summarization
Motivation
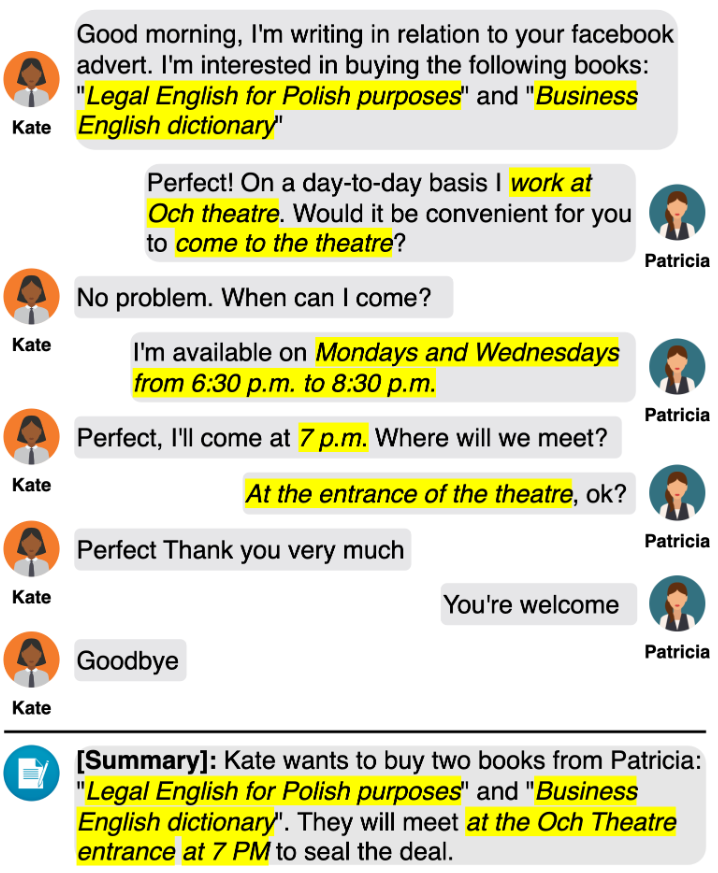
The main challenge of dialogue summarization is to select the most relevant information, that could be spread across different parts of the conversation.
Method
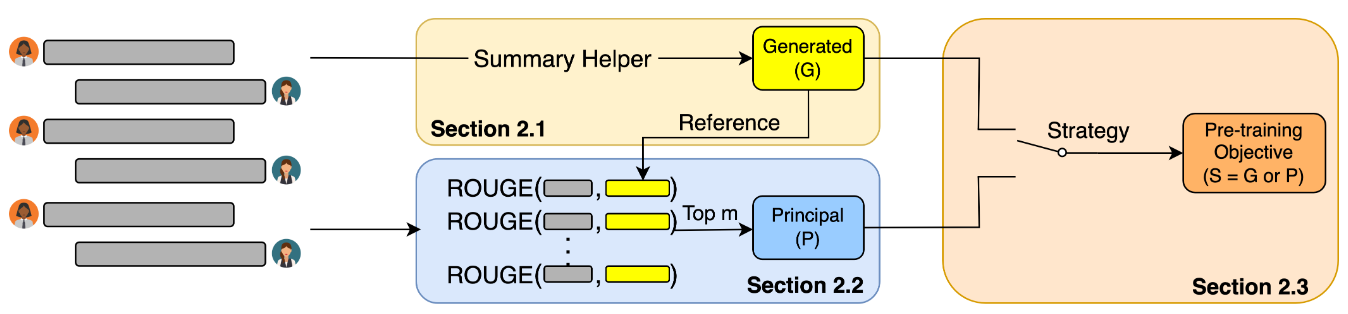
The authors create a pre-training approach for dialogue summarization. For building a pre-training corpus, they use the following algorithm:
- The authors use fine-tuned T5 model for generating pseudo-summaries;
- Then the “Principal” selects messages, that are potential summaries. E.g., when you make a booking, you are asking about a date, time, and place and then at the end, you might get a confirmation message with the full summary. The goal of “Principal” is to find such messages;
- Then “Generator” and “Principal” summaries are evaluated using ROUGE-F1 score, i.e., which summary contains more relevant information?
Results
The approach shows a better performance in zero-shot settings compared to “vanilla” models, like T5.
Faithful Low-Resource Data-to-Text Generation through Cycle Training
Motivation
Fine-tuning LLMs is limited due to its relation to human-annotated data, which is very expensive. Lack of fine-tuning data also leads to hallucinations.
The authors propose a cycle of training for unsupervised pre-training to overcome these issues.
Method
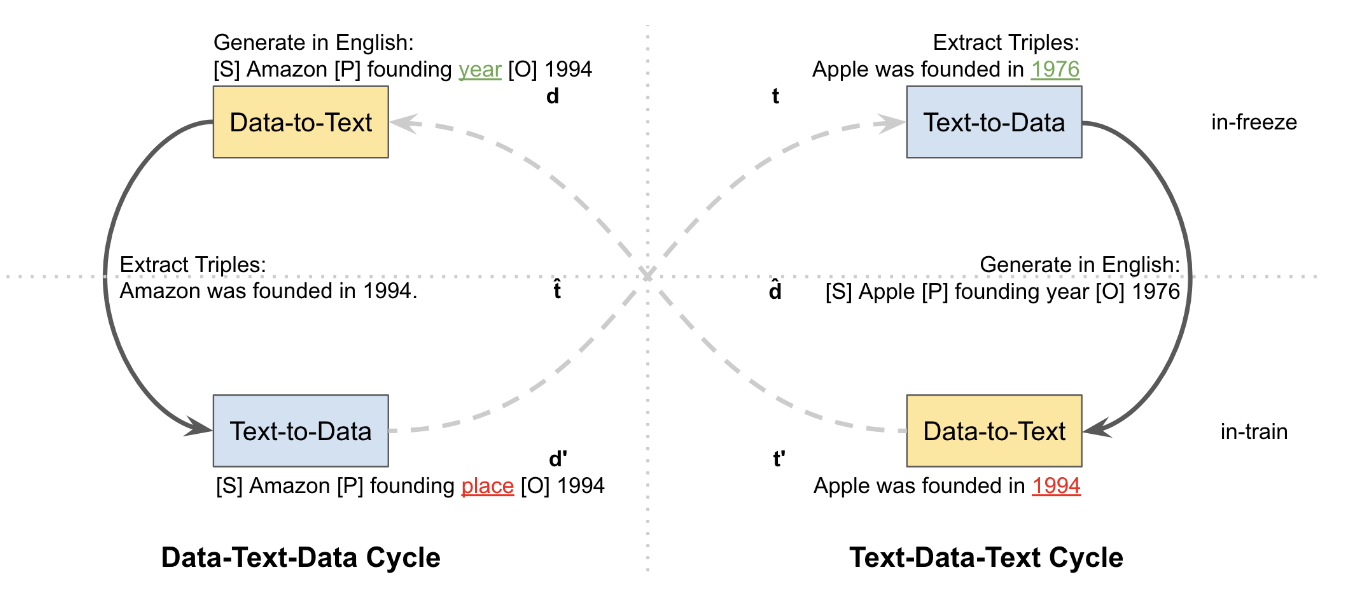
There are two loops:
- Text-Data-Text
- Data-Text-Data
In total, there are 4 models, where 2 remain static (shown at the top) and 2 are trainable (shown at the bottom).
There are 2 training setups:
- Unsupervised cycle training: data triplets and texts are not paired. The goal is to generate data triplet and then generate the initial text or the opposite way - from data to text and back to data;
- Low-resource cycle training: data triplets and texts are paired, but only 100 samples. In this scenario, we are using a full flow without reversing the cycle.
Results
The method shows very good results when it is used in low-resource setup, which is comparable with fully-supervised fine-tuning. The data hallucination is also reduced. (Maybe it could be utilized as an active learning method?)
HyperMixer: An MLP-based Low Cost Alternative to Transformers
Motivation
Recently introduced MLP-Mixer architecture for computer vision got a lot of attention due to its simplicity and low computation costs O(n).
HyperMixer is an adaptation of MLP-Mixer for NLP.
Method
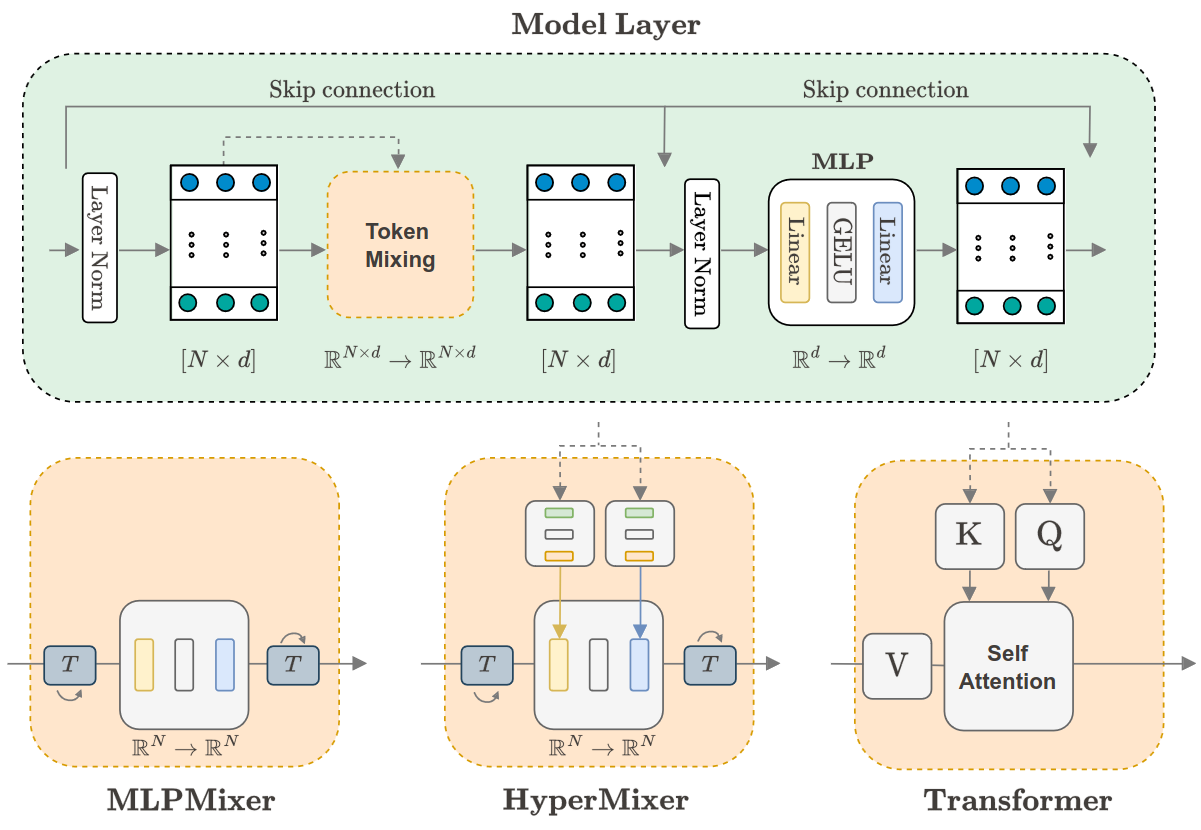
The architecture idea is inherited from Transformer’s attention, where the attention matrix is replaced with a Token mixer.
Unfortunately, the code is not released, so I’m just guessing how it should work;
- We take matrices that should serve us as keys and queries in Transformer architecture. We add positional information to them;
- Then we transpose the keys matrix and multiply it to learnable parameter x;
- An activation function (GELU) is applied on top of the result;
- The query matrix is multiplied by the result of GELU;
- Then the result is fully connected to the values matrix and layer normalisation is applied.
Results
The authors state that the method performs on par with Transformer architecture, but has much less computation costs.
Since the code is not released we can just believe the authors or not.
Linear Classifier: An Often-Forgotten Baseline for Text Classification
Motivation
The hype around LLMs and Transformers makes us forget about the classic methods in NLP such as TF-IDF. The paper analyses the performance of SVM + TF-IDF and BERT to text classification tasks.
Results
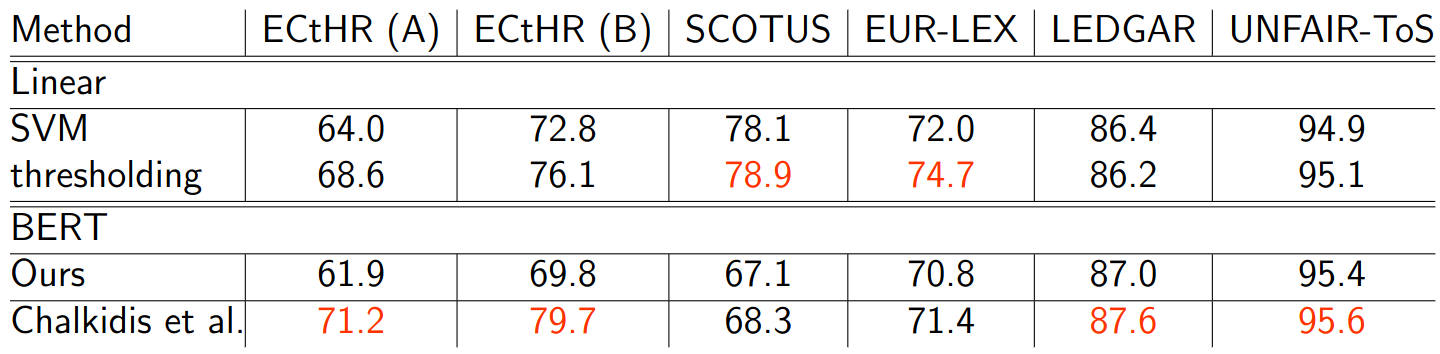
Comparing classification results for various datasets we can conclude, that linear methods can perform on par or even outperform BERT in some datasets.
Taking into account, that Transformer methods are much heavier, i.e., it takes much more time during training and inference, the application of these methods should be always compared with much simpler methods, like TF-IDF, BoW, decision trees, SVMs, etc.
Rogue Scores
Motivation
ROUGE score was introduced in 2004 and become one of the main evaluation metrics for generative language models.
Many tasks use ROUGE evaluation:
- Summarization;
- Question answering;
- Reading comprehension;
- Image and video captioning;
- Other language generation tasks.
The ROUGE score can be configured differently and all of these impact on the final score. If configuration details are not reported, this could lead to difficulties in reproducibility and could cause inappropriate comparisons between models.
The authors tried to answer the question: Do papers report these critical ROUGE evaluation details?
Results
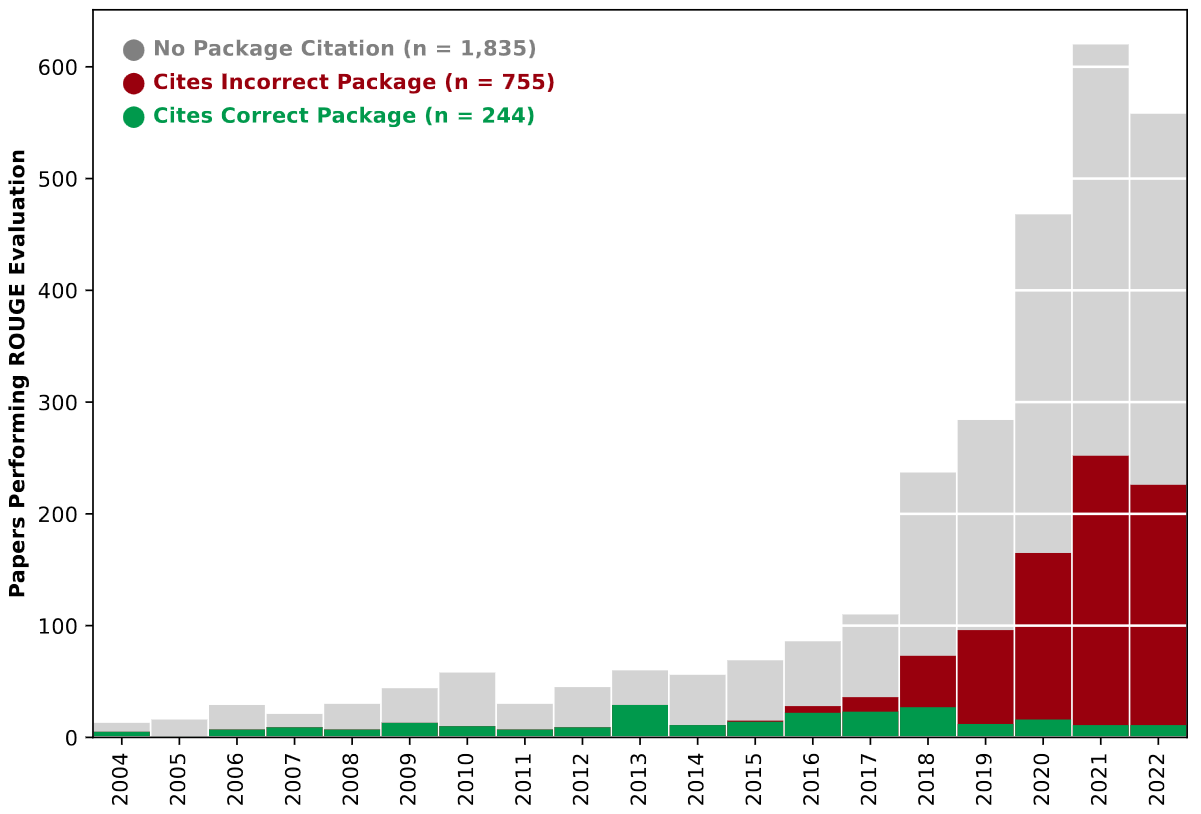
Rogue Scores conducted a systematic review of 2834 papers using ROUGE. As a result, 80% of papers are missing critical evaluation reproducibility details.
Moreover, many papers use a non-standard ROUGE package. The authors evaluated 17 nonstandard implementations and concluded, that 16 out of them compute ROUGE score incorrectly.
HyPe: Better Pre-trained Language Model Fine-tuning with Hidden Representation Perturbation
Motivation
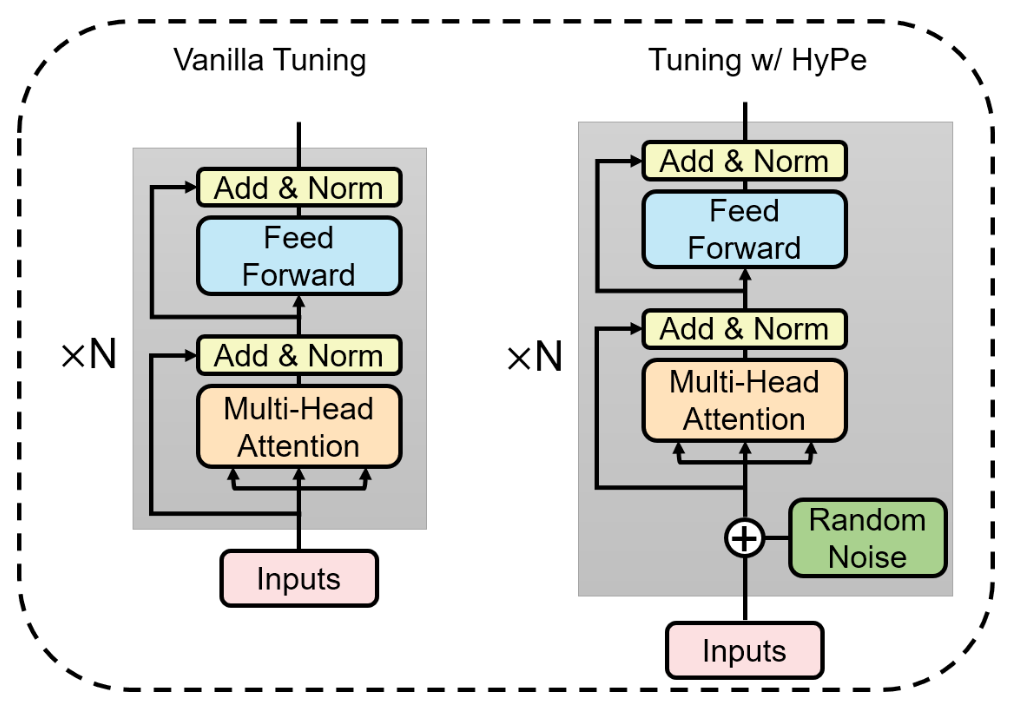
The authors propose adding a small random noise to each hidden layer input. This simple, yet effective technique postpones overfitting and makes the model more robust.
Results
Compared to vanilla fine-tuning, adding random noise helps to outperform the original LM results.
Backpack Language Models
Motivation
Language model interpretability is an open question in NLP.
Backpacks decompose the predictive meaning of words into components non-contextually, and aggregate them by a weighted sum, allowing for precise, predictable interventions.
Method
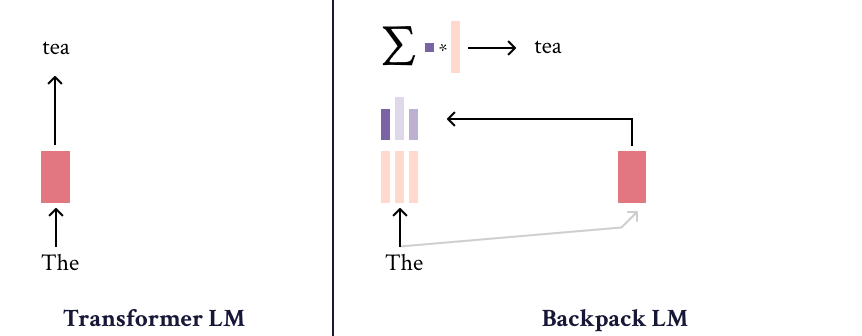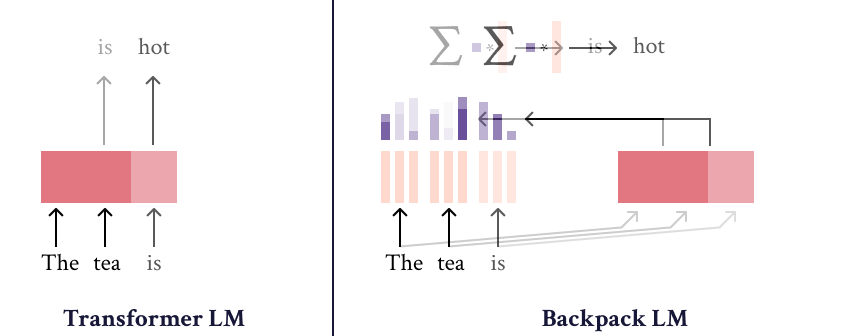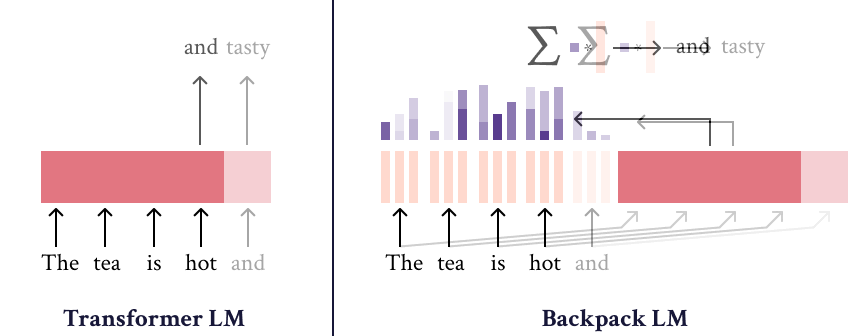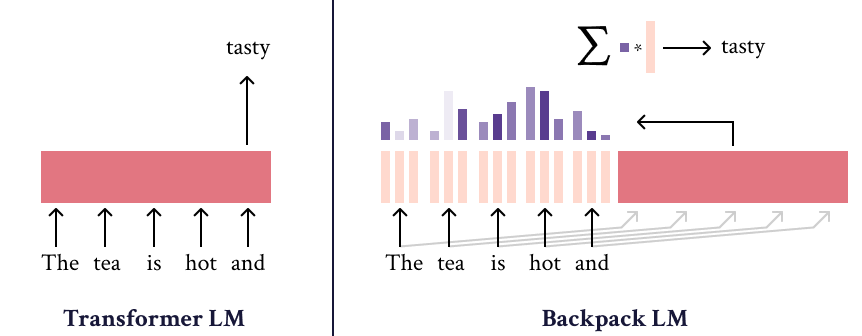
A Backpack model is a neural network that operates on sequences of symbols. It (1) learns a set of sense vectors of meaning for each symbol, and (2) in context, weights and sums each sense vector of that context to represent each word of the sequence.
The method could be applied on top of existing PLMs, like Transformer, to generate weights for the sum. Later the results could be applied for interoperability and control of LMs generation.