When Phrases Meet Probabilities: Enabling Open Relation Extraction with Cooperating Large Language Models
Motivation
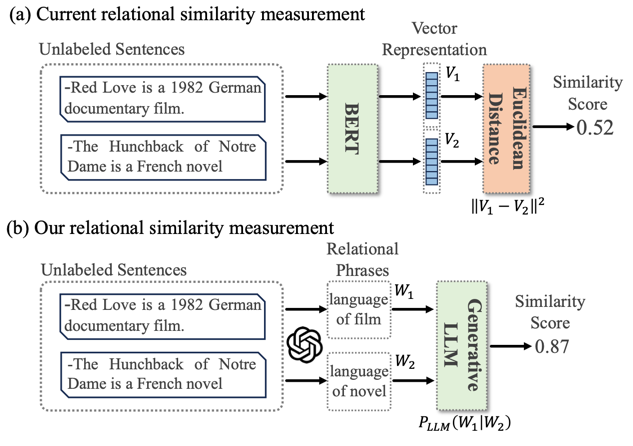 Existing clustering-based open relation extraction methods use pre-trained language models. The embeddings may not accurately reflect the relational similarity.
Existing clustering-based open relation extraction methods use pre-trained language models. The embeddings may not accurately reflect the relational similarity.
Method
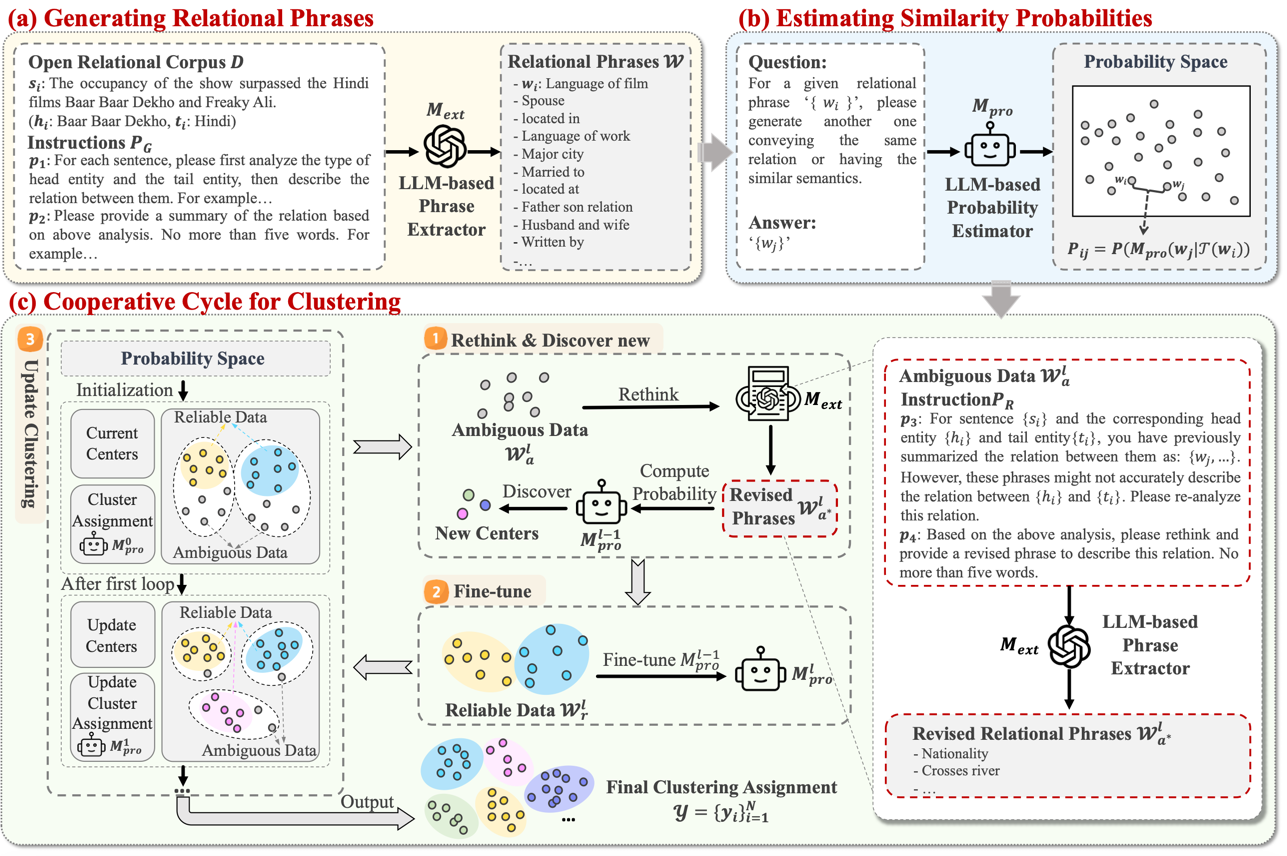 The authors propose a framework that makes two LLMs work collaboratively to achieve clustering. The method consist of the following steps:
The authors propose a framework that makes two LLMs work collaboratively to achieve clustering. The method consist of the following steps:
- Extract phrases using API-based LLM (OpenAI) to generate relational phrases for instances.
- Employing an open-source LLM as a probability estimator to compute the likelihood of one phrase generating another. This procedure outputs a probability space that reflects the semantic similarity among the generated phrases.
- Then there’s an iterative pipeline for filtering phrases based on current clustering results. During each iteration, the ambiguous phrases are rewritten and reevaluated until they become reliable.
Results
The proposed framework outperforms existing methods by 1.4% - 3.13% on different datasets.
KnowCoder: Coding Structured Knowledge into LLMs for Universal Information Extraction
Motivation
The authors propose a universal information extraction method based on fine-tuned LLaMA2-7B. The code and model is available.
Method
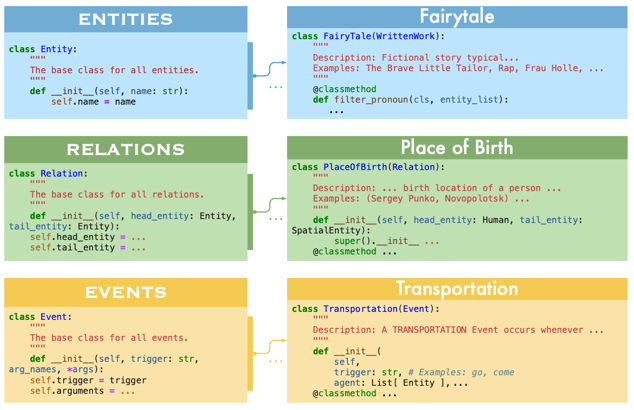 The authors propose a schema that represent entities and relations as python classes and the data is extracted using code generation.
The authors propose a schema that represent entities and relations as python classes and the data is extracted using code generation.
Results
The model and method achieves up to 22% improvements on information extraction tasks.
Balanced Data Sampling for Language Model Training with Clustering
Motivation
Although dataset collection and composition have been addressed, data sampling strategies during training remains an open question. Most LLMs use random sampling.
Method
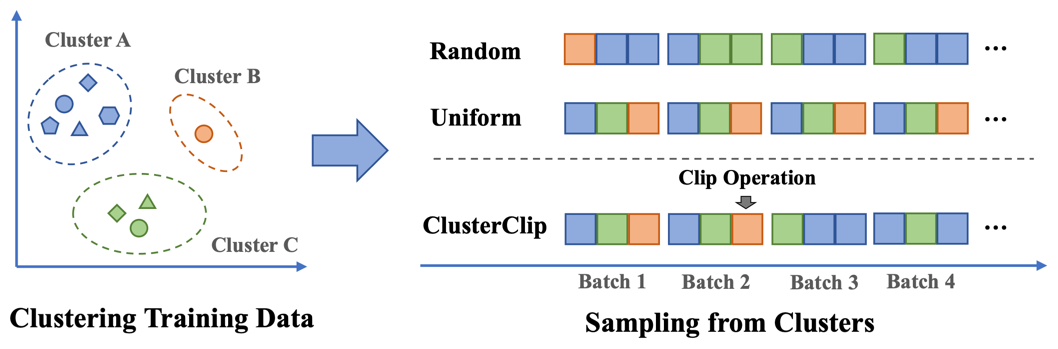 The authors propose ClusterClip, a cluster-based sampling strategy with a clip operation to reduce overfitting. First, data clustering groups semantically related texts to reflect data distribution and assess rarity. In early training, documents from different clusters are sampled evenly to prioritize rare texts. Later, a clip operation removes over-sampled documents, rebalancing the data and preventing overfitting.
The authors propose ClusterClip, a cluster-based sampling strategy with a clip operation to reduce overfitting. First, data clustering groups semantically related texts to reflect data distribution and assess rarity. In early training, documents from different clusters are sampled evenly to prioritize rare texts. Later, a clip operation removes over-sampled documents, rebalancing the data and preventing overfitting.
Results
ClusterClip Sampling, outperforms random sampling and other cluster-based sampling variants under various training datasets and LLMs.
Label-Efficient Model Selection for Text Generation
Motivation
Model selection for a target task is costly due to extensive output annotation. The authors propose DiffUse, a method that uses preference annotations to efficiently choose between text generation models.
Method
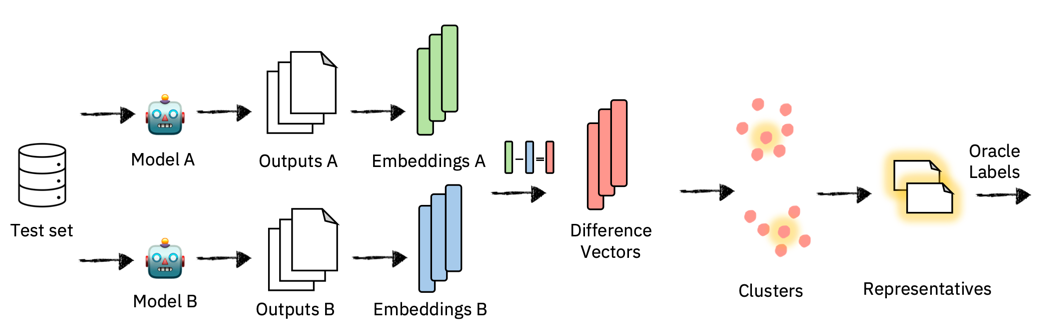 DiffUse efficiently selects text generation models using preference annotations by clustering embeddings of semantic differences between outputs. First, model outputs are embedded into a semantic vector space, and difference vectors are created by subtracting one model’s embedding from another. These vectors are then clustered, and a representative from each cluster is labeled. This approach highlights semantic disagreements between models, helping identify the preferred model.
DiffUse efficiently selects text generation models using preference annotations by clustering embeddings of semantic differences between outputs. First, model outputs are embedded into a semantic vector space, and difference vectors are created by subtracting one model’s embedding from another. These vectors are then clustered, and a representative from each cluster is labeled. This approach highlights semantic disagreements between models, helping identify the preferred model.
Results
In a series of experiments over hundreds of model pairs, the method demonstrate the ability to dramatically reduce the required number of annotations – by up to 75% – while maintaining high evaluation reliability.
Multi-Task Inference: Can Large Language Models Follow Multiple Instructions at Once?
Motivation
LLMs are typically trained to follow a single instruction per inference call. The authors analyze whether LLMs also hold the capability to handle multiple instructions simultaneously.
Method
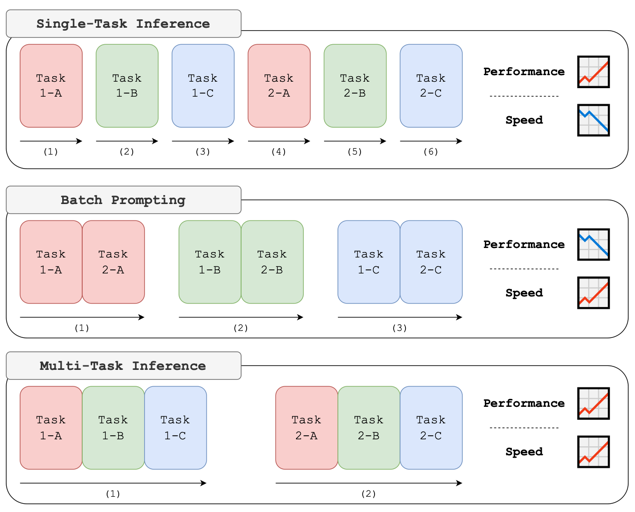 They propose MTI BENCH (Multi-Task Inference Benchmark)
They propose MTI BENCH (Multi-Task Inference Benchmark)
Results
State-of-the-art LLMs, such as LLAMA-2-CHAT-70B and GPT-4, show up to 7.3% and 12.4% improved performance with multi-task inference compared to single-task on the MTI BENCH. Small models (GPT 3.5, LLaMA2-7B/13B) perform worse.
Unlocking Efficiency in Large Language Model Inference: A Comprehensive Survey of Speculative Decoding
Motivation
LLMs have a high inference latency stemming from autoregressive decoding.
Method
They propose a novel decoding paradigm that drafts multiple tokens and verifies them in parallel. They aim to provide a catalyst for further research on Speculative Decoding .
Results
The proposed method drafts multiple tokens and verifies them in parallel. It can be used to accelerate inference in large language models.
EasyInstruct: An Easy-to-use Instruction Processing Framework for Large Language Models
Motivation
The instruction tuning is a crucial technique to enhance the capabilities of LLMs - but there is no standard open-source instruction processing framework available for the community.
Method
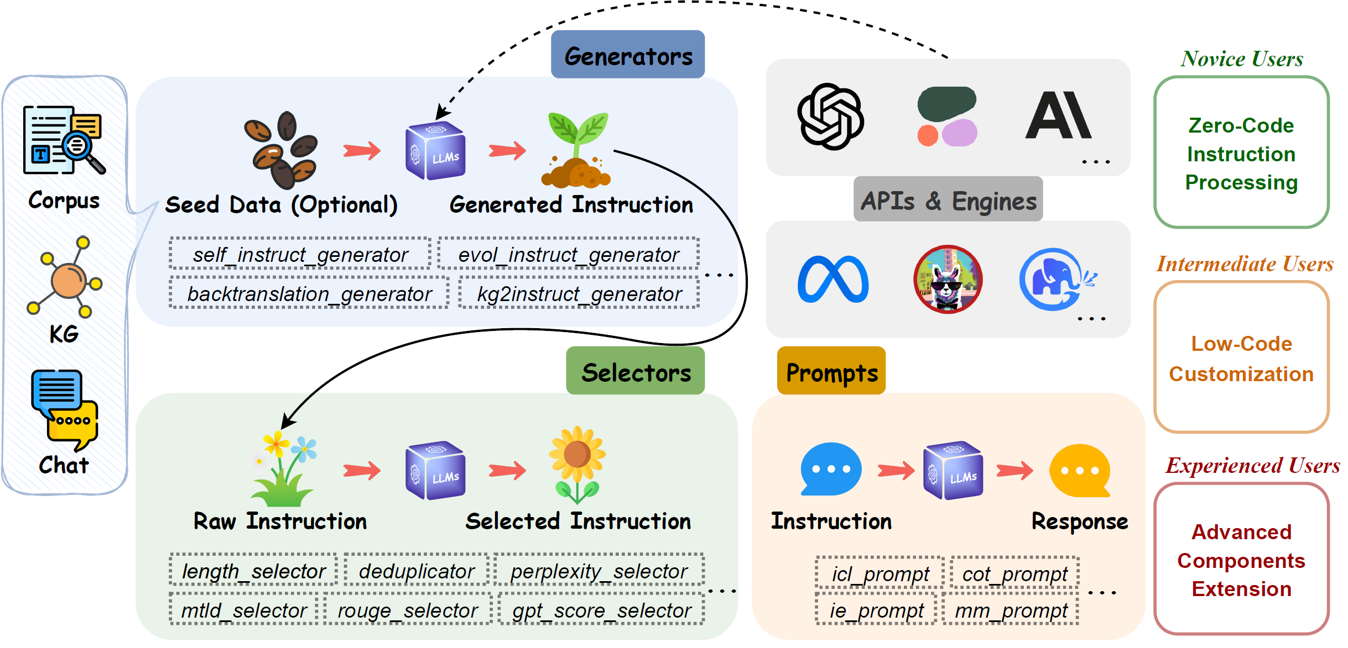 They propose an open-source instruction tuning framework for LLMs that modularizes instruction generation, selection, prompting and their combination and interaction.
They propose an open-source instruction tuning framework for LLMs that modularizes instruction generation, selection, prompting and their combination and interaction.
- The APIs & Engines module standardizes the instruction execution process, enabling the execution of instruction prompts on specific LLM API services or locally deployed LLMs.
- The Generators module streamlines the instruction generation process, enabling automated generation of instruction data based on chat data, corpus, or knowledge graphs.
- The Selectors module standardizes the instruction selection process, enabling the extraction of high-quality instruction datasets from raw, unprocessed instruction data.
- The Prompts module standardizes the instruction prompting process.
The instruction generation methods implemented in Generators are categorized into three groups, based on their respective seed data sources: chat data, corpus, and knowledge graphs. The evaluation metrics in Selectors are divided into two categories, based on the principle of their implementation: statistics-based and LM-based.
Results
The code and demo for the proposed framework is publicly available.
Cache & Distil: Optimising API Calls to Large Language Models
Motivation
Many AI application often depends on costrly API calls to LLMs. The authors propose a method to save costs from the long-term perspective.
Method
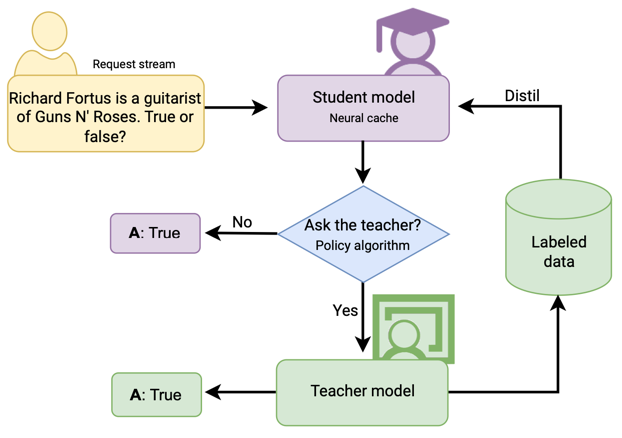 The authors propose to use a local smaller language model – a student. The model is continuously trained on the responses of the LLM. This student gradually gains proficiency in independently handling an increasing number of user requests, a process we term neural caching.
The authors propose to use a local smaller language model – a student. The model is continuously trained on the responses of the LLM. This student gradually gains proficiency in independently handling an increasing number of user requests, a process we term neural caching.
The policy algorithm is a custom classification, that should be driven by your own business requirements.
Results
The authors propose the sample for their solution on GitHub.
Unsupervised Multilingual Dense Retrieval via Generative Pseudo Labeling
Motivation
- Multilingual retrieval enables knowledge access across languages.
- Dense retrievers require large amount of training data, which is hard to acquire.
- LMs exhibit strong zero-shot reranking performance.
Method
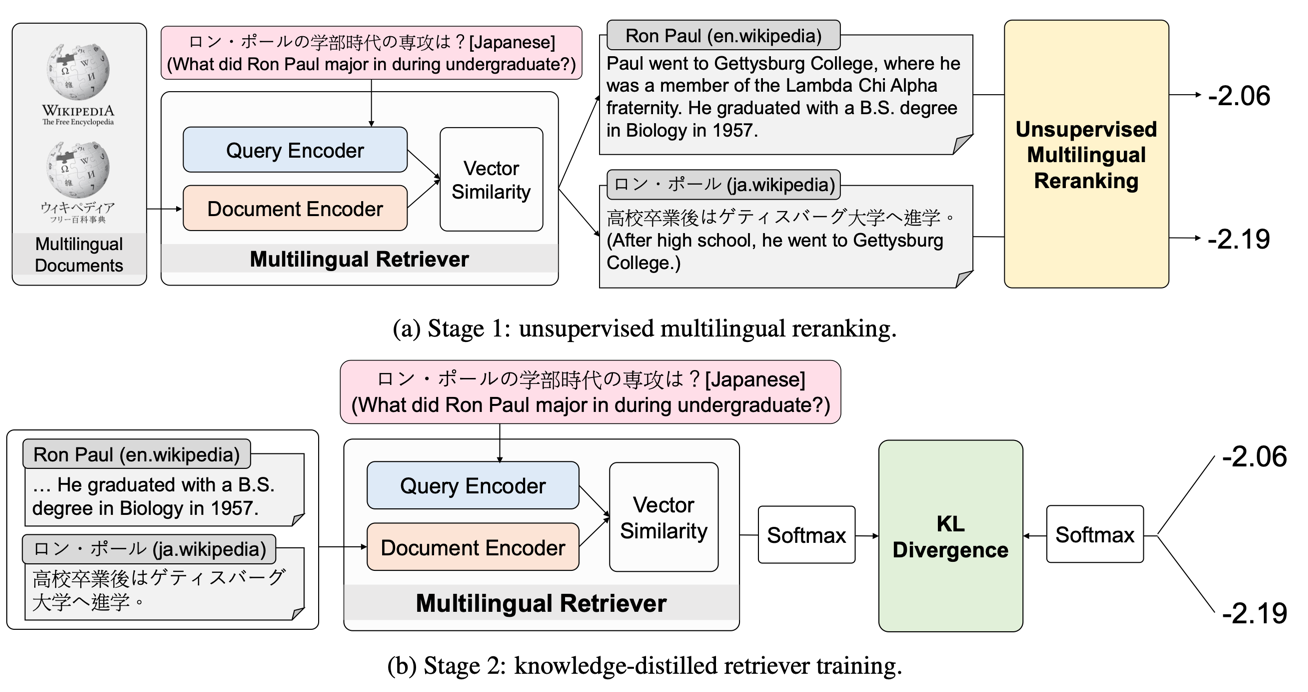 They propose an Unsupervised Multilingual dense Retriever trained without paired data which iteratively improves performance of multilingual retrievers.
They propose an Unsupervised Multilingual dense Retriever trained without paired data which iteratively improves performance of multilingual retrievers.
- Utilize LLMs to rerank the retrieved results via query likelihood.
- Use the LLM scores to train the dense retriever via knowledge distillation.
Results
The proposed framework outperforms supervised baselines on two benchmark datasets and shows that iterative training improves the performance.
The code and models are available on GitHub.
Anonymization Through Substitution: Words vs Sentences
Motivation
Anonymization of clinical text is crucial to allow sharing of health records while protecting patient privacy
Method
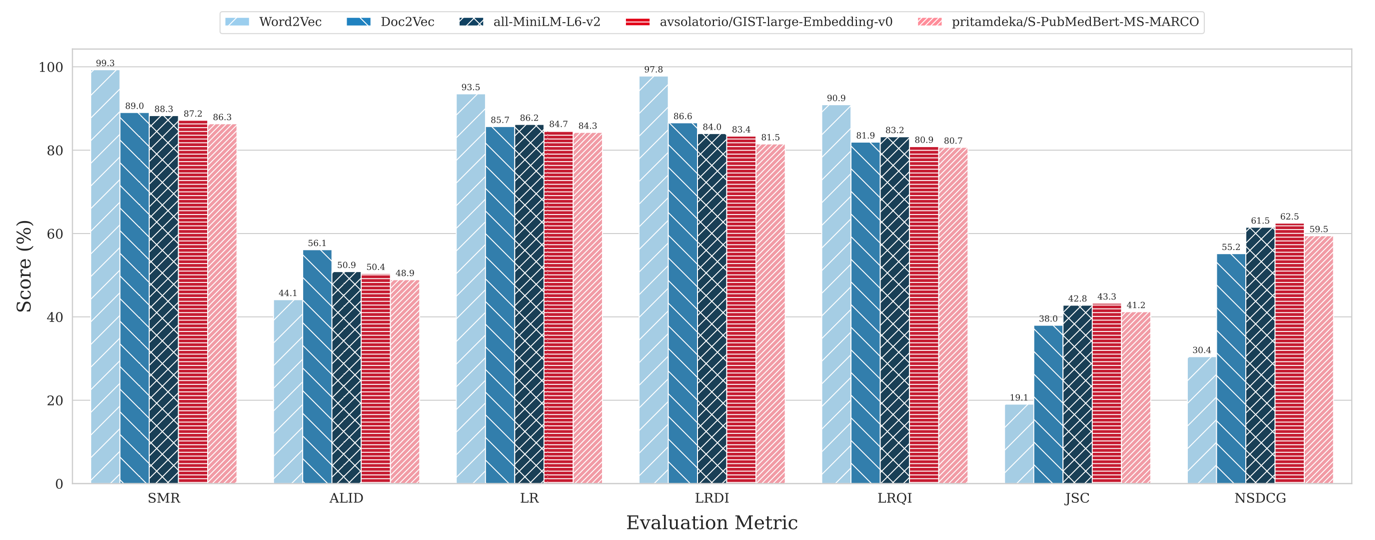 The authors evaluated performance using metrics for anonymization sensitivity and clinical information retention. They compared two anonymization strategies:
The authors evaluated performance using metrics for anonymization sensitivity and clinical information retention. They compared two anonymization strategies:
- Word replacement using Word2Vec embeddings.
- Sentence replacement using Doc2Vec and Sentence Transformer embeddings.
Results
- Word replacement performed better on anonymization metrics but worse on information retention.
- Sentence replacement (especially using Sentence Transformers) achieved better balance of anonymization and information retention.
The authors conclude that both replacement techniques have strengths and are viable alternatives to NER approaches. Although, some relevant information still could be lost after the replacement.