Improving the Robustness of Summarization Systems with Dial Augmentation
Motivation
A robust summarization system should be able to capture the gist of the document, regardless of the specific word choices or noise in the input.
Method
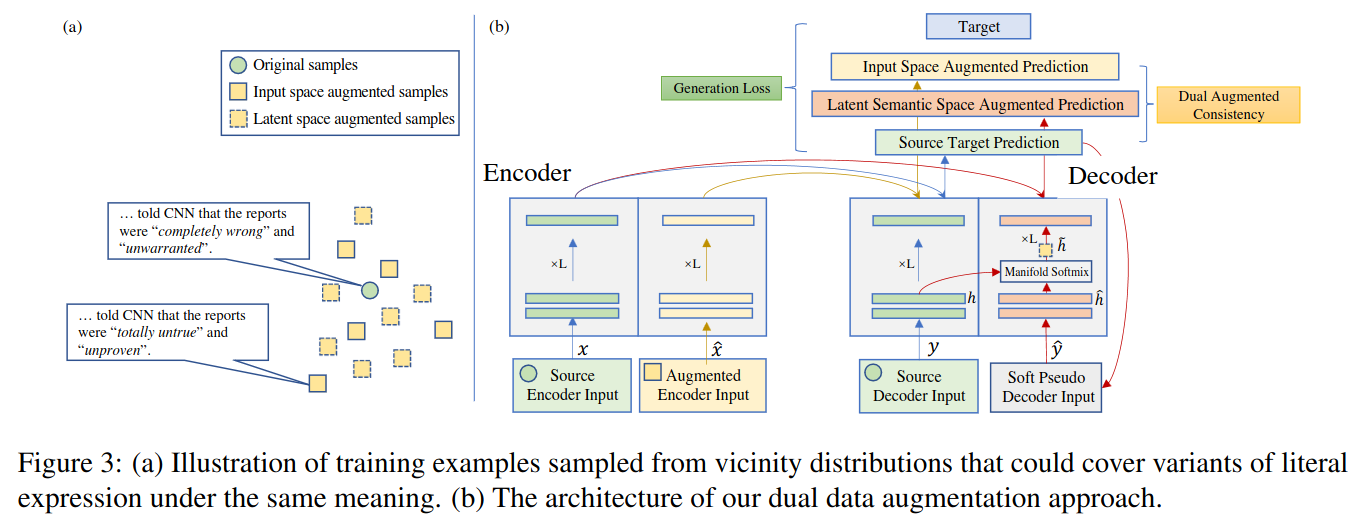
The authors use data augmentation for replacing common words with rare words.
The architecture is the following:
- Transformer Encoder for data augmentation;
- Decoder for summary generation.
Results
The approach performs better than the baseline (i.e., without word replacing). Summarized texts are more diverse and closer to the ground truth.
Peek Across Improving Multi-Document Modelling via Cross-Document Question-Answering
Motivation
Combine multiple textual sources and write a summary for all textual corpus.
Dataset
Contains a set of documents and their gold summaries. The documents are not large and could be named as passages.
Task difficulties
The texts could not just be appended one to another and passed to the model. Multi-document summarization (MDS) system requires:
- Salience and redundancy detection;
- Cross-document information fusion;
- Text planning & generation;
- Modelling cross-text relationships.
Method
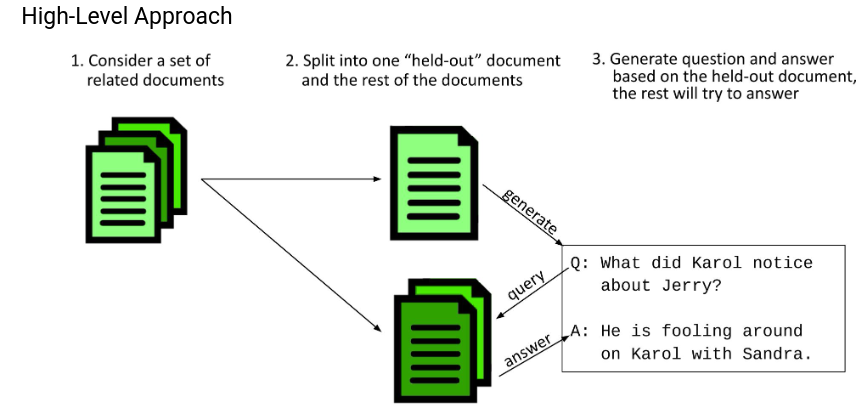
The used method:
- Take one document as a base;
- Out of the base document generate questions;
- Look for the answers in the rest of the documents.
Model overview
The authors fine-tuned large-sized Longformer-Encoder-Decoder. The input size is 4096 tokens and the output is 1024 tokens. (Taking into account not long “document” size, it looks like all the documents were able to fit into the model input. However, the encoder local attention window was limited to 1024 tokens and was sliding across the input.)
Results
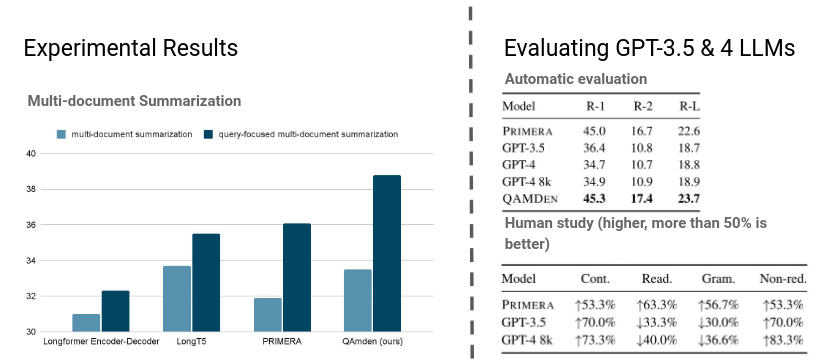
The fine-tuned model was able to outperform LLMs (GPT-3.5 & 4 were working in zero-shot mode) and fine-tuned LongT5 and PRIMERA.
Toward Expanding the Scope of Radiology Report Summarization to Multiple Anatomies and Modalities
Motivation
Multiple radiologists must validate the final impression, that is written based on findings.

In the paper, the authors focus on generating the impression (conclusion), assuming that the findings are given.
Dataset
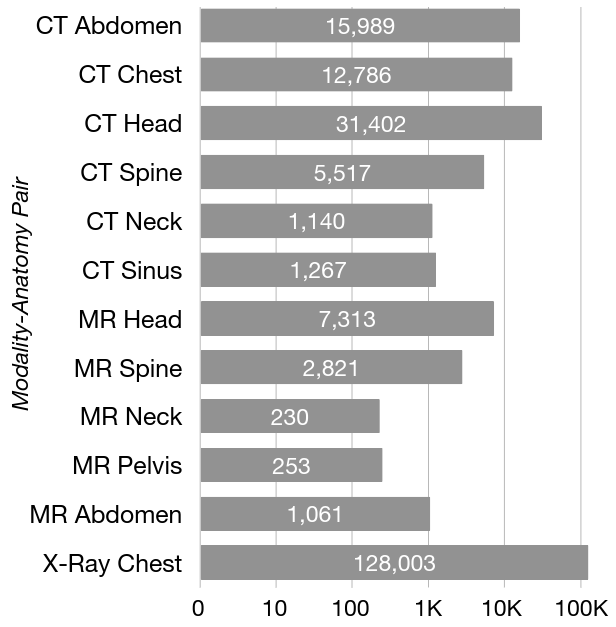
The authors introduce a new open-source MIMIC-RRS dataset which could be used for radiology report summarization (RRS). It contains 207k reports from 12 modality-anatomy pairs.
Task difficulties
Previous works were mostly focused on single anatomy and modality (e.g., chest X-rays), as well as using private datasets.
Evaluation
The authors introduce RadGraph score which aims to provide an evaluation of the factual correctness and completeness of a generated impression. The metrics are inspired by RadGraph dataset (Jain et al., 2021). It contains chest X-ray reports annotated by board-certified radiologists. The annotations consist of a graph representation of entities in the summary and their relations. The score itself is similar to F1 score and was validated by one radiologist, i.e., is very subjective.
Using the metric, the authors evaluated fine-tuned LM (BART, T5) and concluded, that modern pre-trained language models (PLMs) are effective baselines for RRS, compared to prior models.
APOLLO: A Simple Approach for Adaptive Pretraining of Language Models for Logical Reasoning
Motivation
Propose a new approach for pre-training/fine-tuning LMs that will be able to do logical reasoning by inferring the input text. Later this ability could be utilized for more reasonable answer selection/generation.
Method

Instead of random masking the words for unsupervised training, select specific words, that could be inferred by the logical context. The authors select words for masking if they’re preceding or following some specific keywords (e.g., therefore, accordingly, but, although, etc.)
Results
The approach performs better than the baseline, but worse or on par than the other approaches. It could mean that the approach works, but should be combined with other approaches or should be enhanced further in order to show marginal upgrade.
Going Beyond Sentence Embeddings: A Token-Level Matching Algorithm for Calculating Semantic Textual Similarity
Motivation
Comparing sentences’ semantic similarity is still an unsolved issue in NLP. Current methods, such as MoverScore or all token cosine distance are still far from being perfect for measuring sentence semantic similarity. Moreover, the methods do not take into account token importance. Articles, prepositions, etc. usually contribute lower semantic value to the sentence.
Method
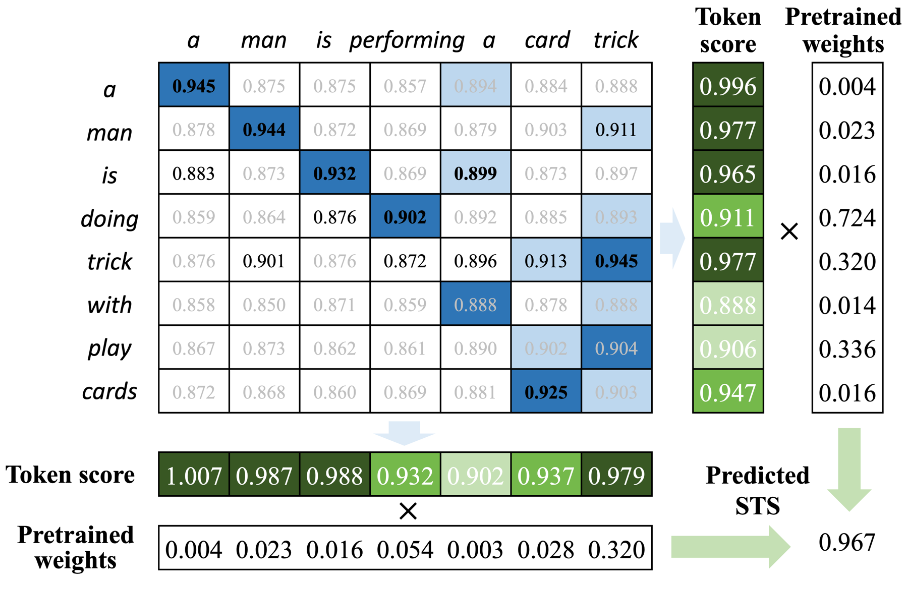
The authors propose a combined approach:
- Calculate token-level similarity matrix (using any LM);
- Calculate the token matching score. Measures the likelihood that a given token in one sentence can be matched to a token in the other sentence;
- Calculate token weighting. Measures the semantic importance, that a given token contributes to the whole sentence semantic.
Results
The authors applied the method to existing semantic textual similarity datasets and models. In most cases, the model with the proposed method performed better, than the original model. (However, I’d say that the method needs empirical study and should involve more human evaluation.)
Did You Read the Instructions? Rethinking the Effectiveness of Task Definitions in Instruction Learning
Motivation
Modern LLMs are able to perform very well in few-shot and even zero-shot learning, i.e., when you give an instruction to LM (zero-shot) or provide input-output samples (few-shot).
In the paper, the authors study the instruction effectiveness and propose an algorithm for compressing task definitions. (Brief task definitions are very crucial, taking into account, that generative LLMs, such as OpenAI’s GPT, are charging for input token length as well.)
Key findings
Which parts of task definitions are important when performing zero-shot instruction learning?
- For classification tasks, label-related information is crucial, as it helps the model identify the output space and identify each label’s meaning when generalizing;
- Additional details or constraints besides primary mentions of input and output, in general, do not improve model performance. As model size increases, additional details become important;
- Task definitions can be extensively compressed with no performance degradation, particularly for generation tasks.
Is natural language the most efficient format to communicate task instructions to models?
- Framing instructions as a structured input/action/output triplet is potentially a more efficient and effective way of creating task definitions;
- In fact, using only basic metadata and the label space (without label definitions) in a structured format, we achieve similar, or even better performance as with full definitions.
How can we improve models’ understanding of definitions as well as model performance?
- Adding a meta-tuning stage for adapting models to the writing styles of definitions improves the performance.
Method
The automatic algorithm should be released here. It is based on a syntactic tree and leaf reduction algorithm for evaluating the most important words in the sentence.
An example of an automatic instruction algorithm, where retained content is highlighted in green:

Results
The authors show that task instructions should be brief and shouldn’t sound very natural to humans. LLMs may grasp the idea of the task, by just seeing some keywords or input/action/output examples. Long task descriptions are especially useless for generative tasks.
Automated Metrics for Medical Multi-Document Summarization Disagree with Human Evaluations
Motivation
There are no effective automated evaluation metrics for multi-document summarization for literature review (MSLR) The MSLR task goal is to accept several documents as inputs and generate a summary of all the documents.
The authors created a human-annotated dataset for MSLR metric evaluation taking into consideration various facets of evaluation:
- Fluency: Is the generated text fluent?
- PIO: Are the populations, interventions, and outcomes discussed in the text consistent with the reference?
- Direction consistency: Is the direction of effect consistent?
- Strength consistency: Is the strength of the claim consistent?
MSLR metric evaluation
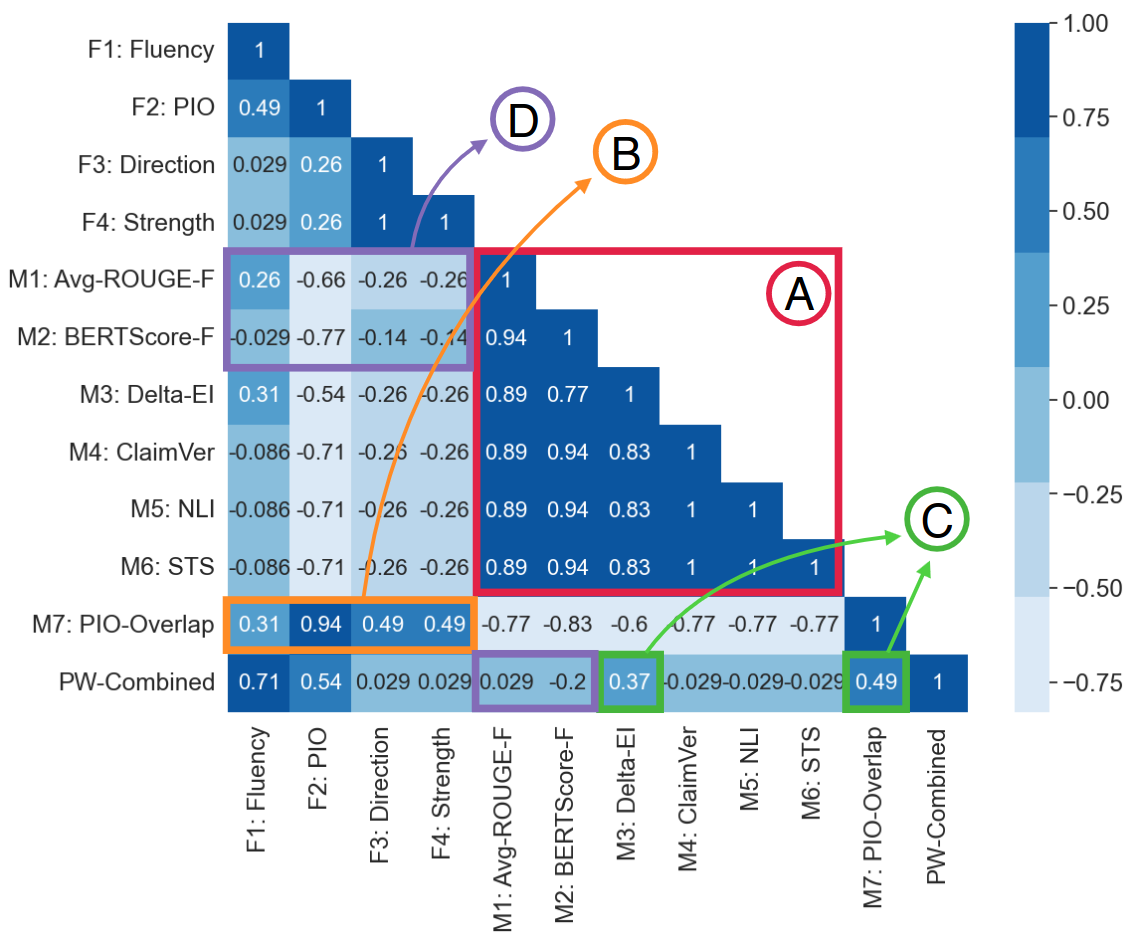
Used metrics:
- F1-F4: Human-assessed quality facets;
- M1-M7: Automated metric;
- PW-combined: combined pairwise system ranking on the Cochrane MSLR dataset.
Main takeaways:
- Rankings from automated metrics are highly correlated as a group except for PIO-Overlap (A);
- PIO-Overlap (new proposed automated metric, that could be found in the same repository as data) rankings are strongly correlated with rankings from human-assessed facets, especially PIO agreement (B);
- Metrics most strongly associated with PW-Combined rankings are Delta-EI and PIO-Overlap (C).
- Rankings from commonly reported automated metrics like ROUGE and BERTScore are not correlated or anti-correlated with human-assessed system rankings (D).
Annotated dataset (medical domain) for metric evaluation could be found here.