Generating Text from Language Models
📝 Slides
Definition: Language Model is a probability distribution over strings.
Objective of language generators: Steer strings distributions towards text with specific attributes without retraining/fine-tuning the language model. Or, in simple words, make the language model to generate what we want without compute intensive model retraining.
Discrete distributions
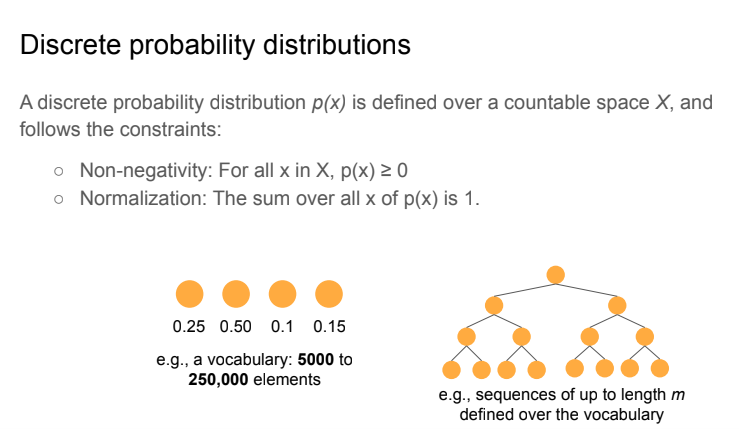
Distributions could be classified into “small” (on the left, used for vocabularies) and “large” (on the right, used for chain-of-thoughts).
Entropy
Definition: measures uncertainty of the probability distribution. The higher uncertainty, the higher entropy.
Example of entropy value for language generation tasks
Scenario 1 (document generation, news generation):
- Distribution: web documents
- Entropy: high
- Good generations: many
Scenario 2 (machine translation):
- Distribution: sentence translations
- Entropy: low
- Good generations: few
Entropy definition equation

LM evaluation
The quality of LMs is usually measured with perplexity (the lower, the better). It basically means “how far from the top the ground-truth token is.”
LM evaluation shortcomings
- Difficult to measure what exactly the LMs learn about the language;
- LMs could “hallucinate” (produce wrong facts without warning);
- Often, researchers/developers are not working with super large LMs, because of limited budget.
Text generation
The generation of tokens usually happens autoregressively (token-by-token).
E.g., you pass string <BOS>* my to the LM, and it provides you with a probability distribution, what token most likely will come next.
(* BOS - beginning of the string)
Scoring functions
Selecting the right next token is not that obvious. It depends on our objectives and the token with the highest probability not always that we want.
Top-k sampling
Simply truncate the tail by selecting the k tokens with the largest probability.

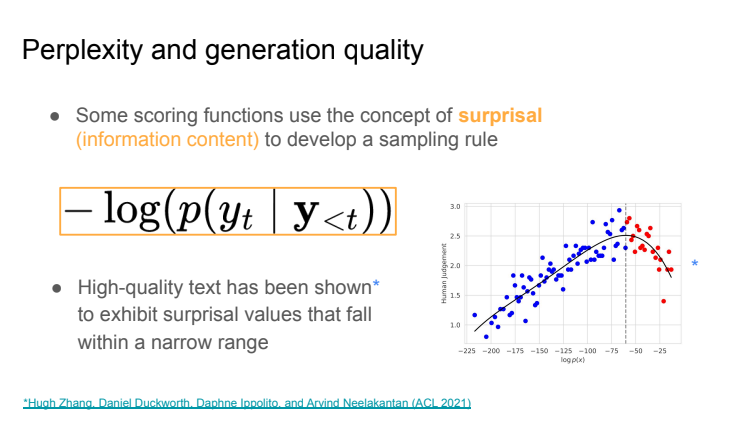
Perplexity and generation quality
Tune k so that the surprisal of the generated text is close to a target value τ
Nucleus sampling
Select tail size dynamically by only considering the nucleus of the distribution.

Prompting
This is the way of steering the LM generation into required direction by providing more context.
The main reason why prompting is working is because context (often) lowers the entropy.
Prompting examples
(The LM will accept the following as input and will finish the sentence.)
Translation:
English: My name is Edward. French:
Summarization:
Toronto police reported …
TL;DR:
Demonstrations (concatenate x,y pairs and give them as model input, i.e., few-shot learning)
Tweet: “I hate it when my phone battery dies.”
Sentiment: Negative
Tweet: “My day has been 👍”
Sentiment: Positive
Tweet: “This is the link to the article”
Sentiment: Neutral
Tweet: “This new music video was incredibile”
Sentiment:
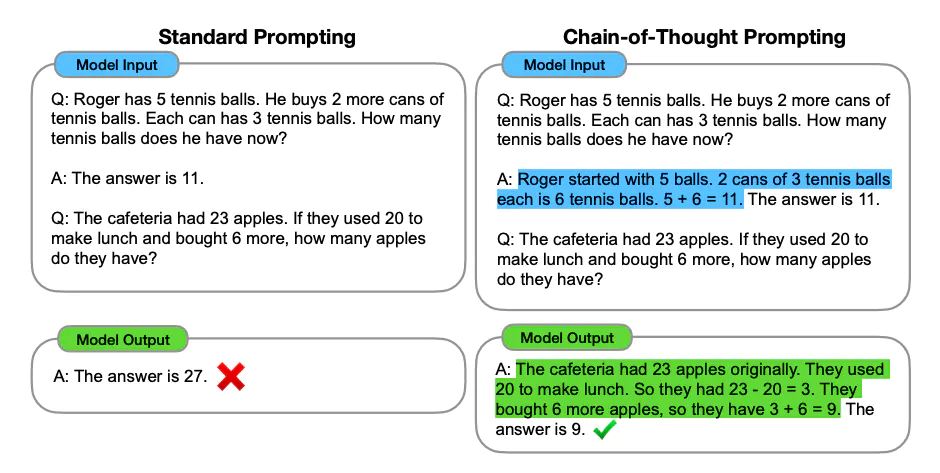
Chain-of-Thought
Controlled generation
Using a set of scoring functions and algorithms to change the token probability distribution towards the desired output.
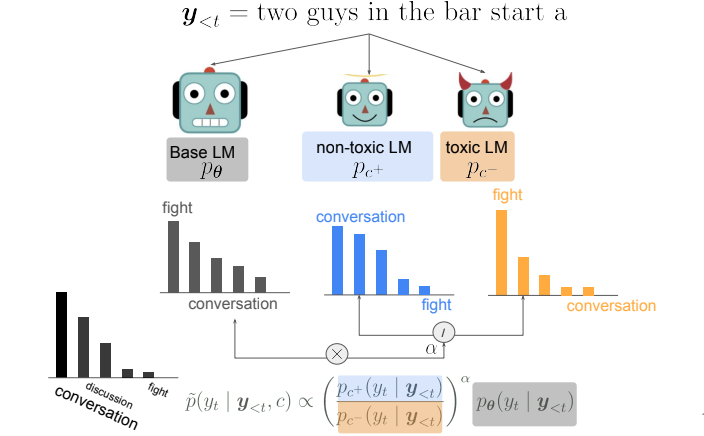
DExperts: Decoding-Time Controlled Text Generation with Experts and Anti-Experts.
Combine the outputs from Anti-Experts and Experts, lowering the most probable tokens from Anti-Experts.
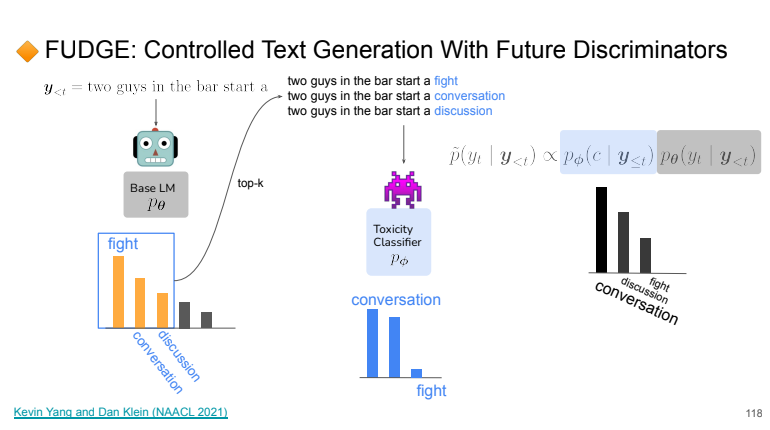
FUDGE: Controlled Text Generation With Future Discriminators
Using classifiers for eliminating tokens that we don’t want.
Energy functions
Guiding the generation to regions with minimum energy, i.e., increasing specific tokens probability.
Measuring the quality of generations
Low-entropy Text Generation Evaluation
- Exact match between generation and ground-truth tokens (mostly not applicable in real-world applications);
- Levenshtein distance: minimum number of edits required to change a string into another;
- BLEU: how many n-grams are in generated text (still used, but the main shortcoming of the approach is that semantically agnostic, i.e., texts could be semantically similar, but used words are very different. Thus, BLEU score is low.);
- BERTScore: generates embeddings using LM (e.g., BERT) and then compare similarity (e.g., cosine distance). This metric takes semantics into account;
- Mauve (Pillutla et. al. 2022) is a language generator evaluation metric that empirically exhibits high correlation with human judgments. Uses clustering for generated embeddings, get distributions from them and then compute similarity.