Attending ACL 2023 in Toronto and will publish my notes here. If somebody is also here, I will be happy to chat in-person.
Complex Reasoning in Natural Language
📝 Slides
Definition: The ability to make a decision based on a chain of presumptions. This is the way how humans think and judge.
Knowledge augmentation for reasoning in language
Knowledge could be:
- Structured (Wikidata, DBpedia, ConceptNet, ect.)
- Un/Semi-structured (Wikipedia, wikiHow, arxiv, PubMed, ect.)
- Parametric knowledge (encoded in the language models) (LAMA, GPT, etc.)
Utilizing language models (LMs) for structured knowledge
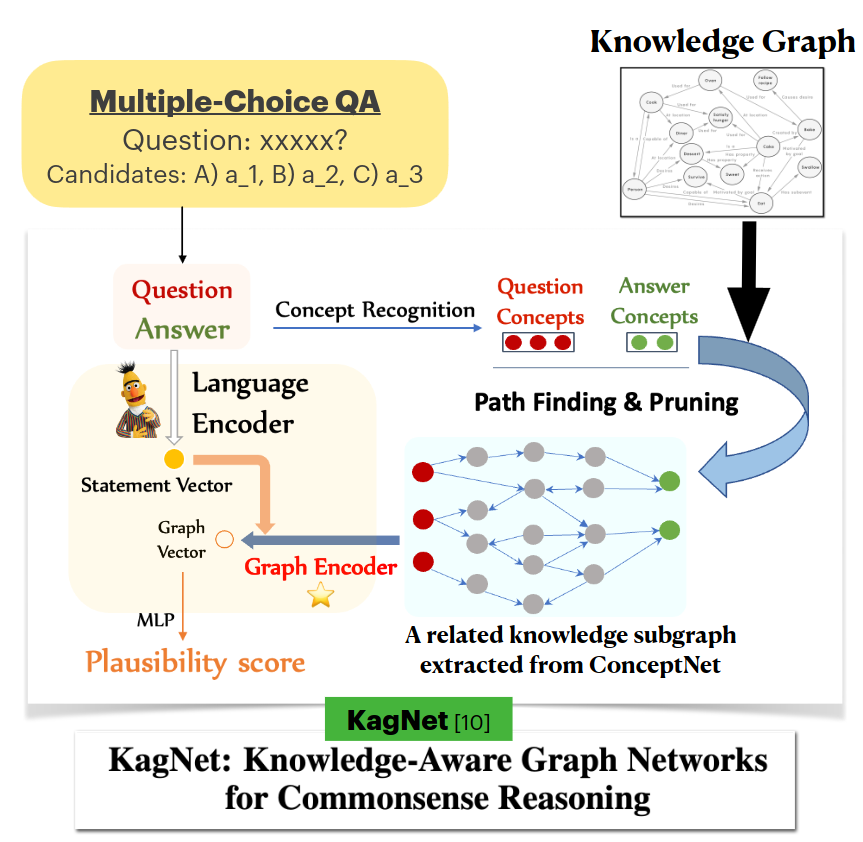
- LMs encodes question + candidates
- Graph encoder build a representation for a subgraph
- Both text and graph embeddings gets fused
- The output gets evaluated.
Un/Semi-structured knowledge
The basic idea: Un/Semi-structured knowledge is split into passages, that could be encoded with LMs. Then these passage vectors could be indexed, evaluated by similarity (e.g., cosine distance), etc.
Parametric knowledge
Structured, Un/Semi-structured knowledge is very accurate, easy to modify, trustworthy, and verifiable, but is incomplete & hard to query!
Parametric knowledge (encoded in the LMs), easy to query, but often hallucinate and make mistakes.
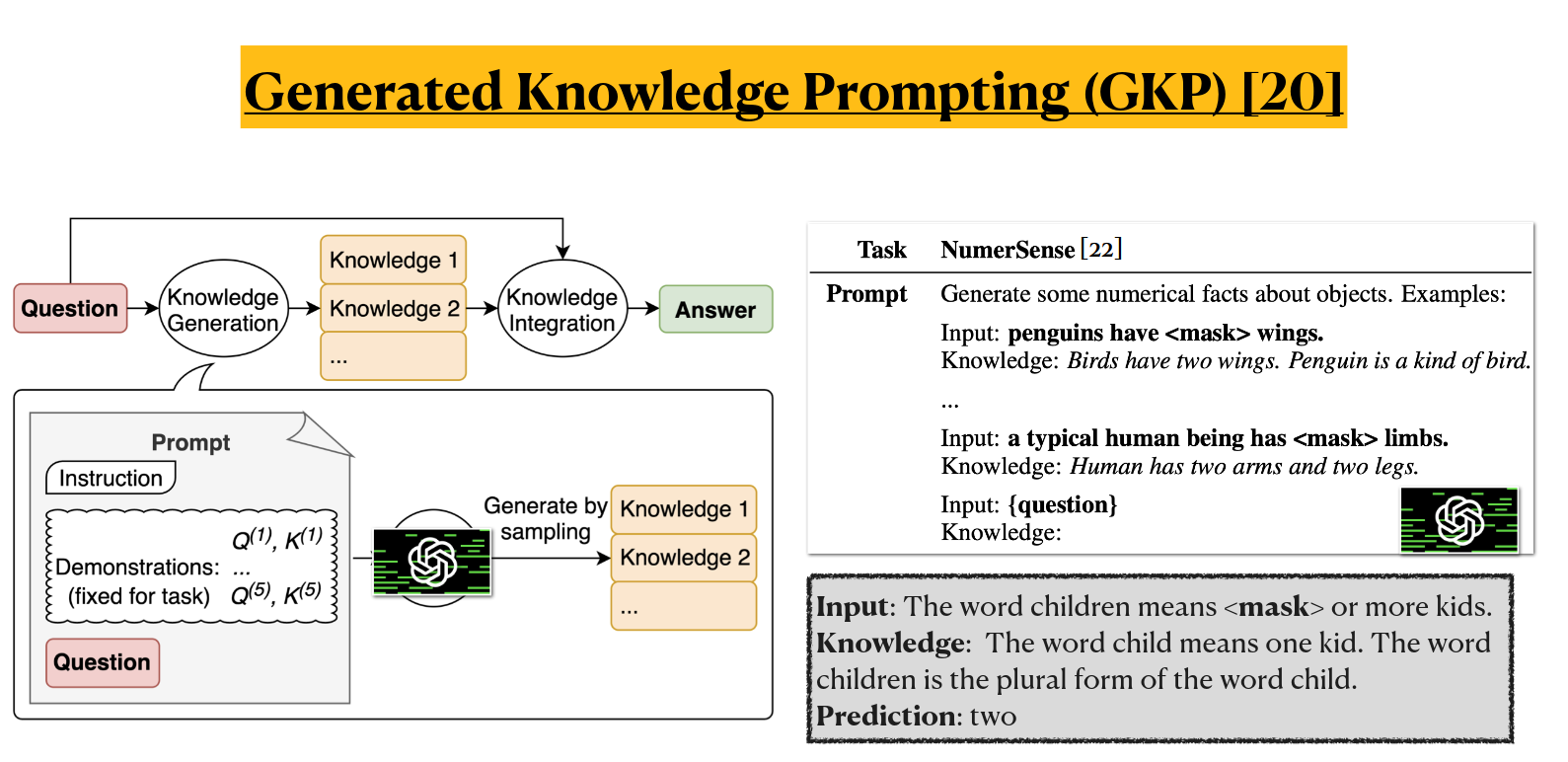 The solution is to combine positive things from both worlds. Create a prompt, that will contain facts (passages from knowledge bases), and then let a generative model to answer the question.
The solution is to combine positive things from both worlds. Create a prompt, that will contain facts (passages from knowledge bases), and then let a generative model to answer the question.
Knowledge-Augmented PreTraining for Reasoning
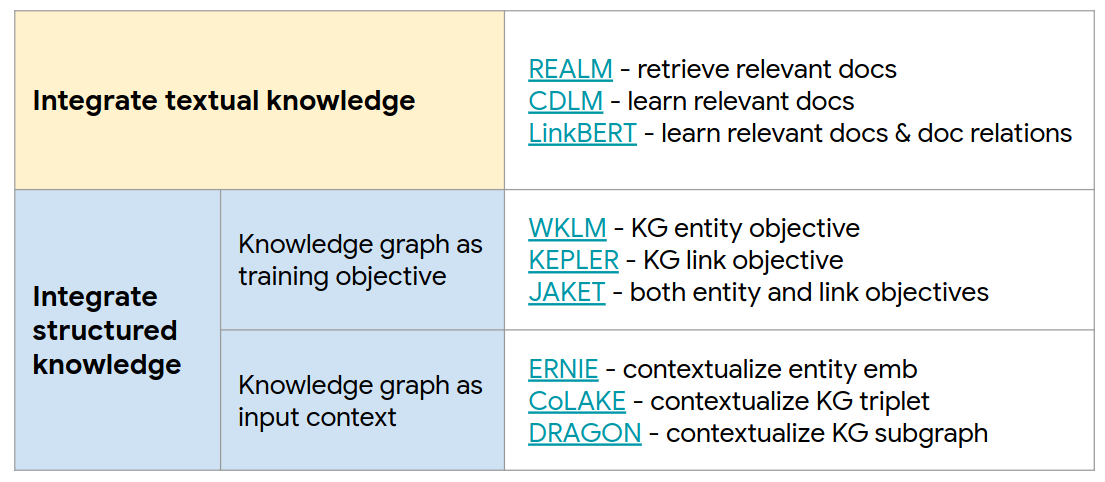
Knowledge helps complex reasoning. Usually multiple facts and knowledge sources are used for solving problems.
The objective of pre-training on augmented knowledge is to make a more diverse outputs and reasoning.
There are a plenty of methods and algorithms for pre-training:
![Pre-training on augmented knowledge]()
Multilingual LLMs
📝 Slides
Evaluation Methodologies
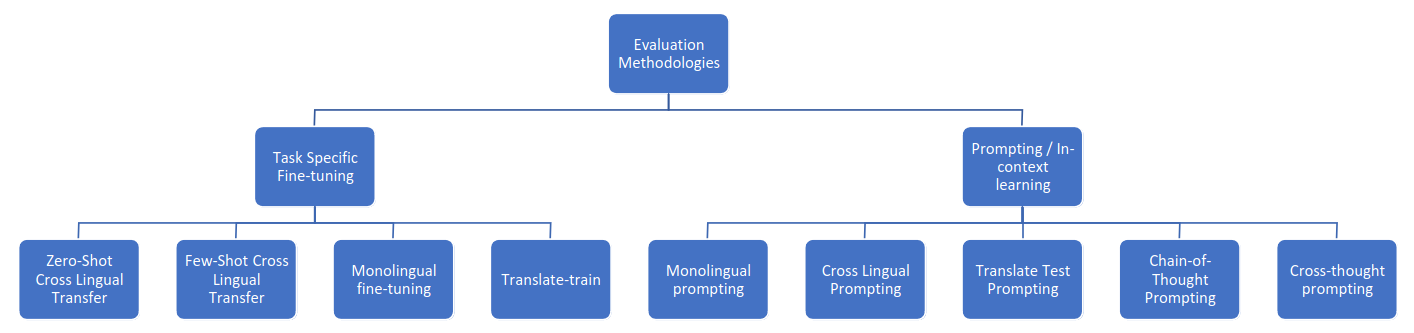
- Zero-Shot Cross Lingual Transfer: Fine-tune model with task specific data in a source language (often English) and test on different target languages directly.
- Few-Shot Cross Lingual Transfer: Fine-tune model with task specific English data and a few training examples in the target language that we wish to evaluate the mode on.
- Monolingual fine-tuning: Fine-tune model with task specific data in target language.
- Translate-train: Fine-tune model with task-specific data in source language translated to target language using MT.
- Prompting / In-context learning: Not involves fine-tuning, just provide extra context in the prompt (E.g., English: some text, French:) and evaluate the output
CheckList: A task agnostic method to test capabilities of NLP systems
A set of methods for evaluating LLMs on specific behaviors. Inspired by behavioral testing in software engineering.